
Mas primeiro, o que é Refactory?
Refatoração (do inglês Refactoring) é o processo de modificar um sistema de software para melhorar a estrutura interna do código sem alterar seu comportamento externo.
Refactory é uma técnica muito utilizada hoje por diversos programadores, metodologias e grupos de desenvolvimento open-souce. Basicamente, consiste em pegar um código e melhorá-lo, escrevendo de forma mais simples e legível, ao mesmo tempo que pode empregar novos conceitos de programação, mas sempre mantendo o mesmo funccionamento básico do sistema.
E o que é o Sharebook?

Sharebook é um projeto capitaneado pelo Raffaelo Damgaard. Eu vi um post sobre o projeto no LinkedIn e acabei indo conhecer mais. Basicamente, sua ideia era de criar um projeto onde a própria comunidade ajudaria a criar a ideia, inclusive código. Deixo abaixo as palavras do mesmo sobre o projeto (o texto completo encontra-se aqui: https://www.linkedin.com/pulse/projeto-sharebook-raffaello-damgaard/)
O que é o Sharebook? Vou falar um pouco sobre o projeto. Tudo começou com meu amigo Vagner Nunes que ajudou um cara humilde que nunca tinha ganhado um livro na vida. Pode até parecer pouco, mas tem muita gente que esse simples gesto faz uma grande diferença. Pessoas humildes que não tem condições e tem até vergonha de pedir.
De certa forma quero me inspirar no UBER. O uber não tem carro próprio. Ele junta as pontas. Eh isso que vamos fazer. O livro não vai passar pela nossa mão. O doador vai cadastrar o livro em nosso sistema. Nós vamos avaliar e aprovar. Aí o livro vai para nossa VITRINE ( website e apps ).
Então depois que o livro está na vitrine ele fica lá até aparecer um interessado. O doador eh notificado e envia. Mas o interessado passa a ser o novo dono do livro? Depende. Livros muito procurados vai ser via empréstimo. Os demais são doação. Eh tipo um ciclo.
Um dos pontos que também me chamaram bastante atenção foram os 3 princípios que ele criou o projeto:
- Não se confundir com um projeto comercial. A essência é ser um serviço grátis para ajudar quem precisa. Um projeto colaborativo de código aberto. Podemos e vamos ser bons e agressivos no marketing, mas sem jamais esquecer essa base.
- Manter as coisas simples e incentivar o aprendizado. Nossa estrutura precisa ser simples ao ponto que mesmo um iniciante rapidamente entenda e se sinta confortável em colaborar no código fonte. Design simples e código limpo.
- Tem que ser divertido como um game. Ganhando pontos. Subindo de nível. Ganhando selos de conquistas. E quem sabe, no futuro, algum parceiro possa patrocinar os prêmios? ( prêmios pro time de desenvolvimento também, claro. )
E com isso, eu resolvi começar a ajudar.
O início
Uma das novas coisas que o Sharebook trouxe para mim foi o Slack. Apesar de já ter ouvido falar na ferramenta, eu não tinha utilizado ela. Não senti muita dificuldade, dado a semelhança com o Microsoft Teams, que uso na empresa que trabalho.
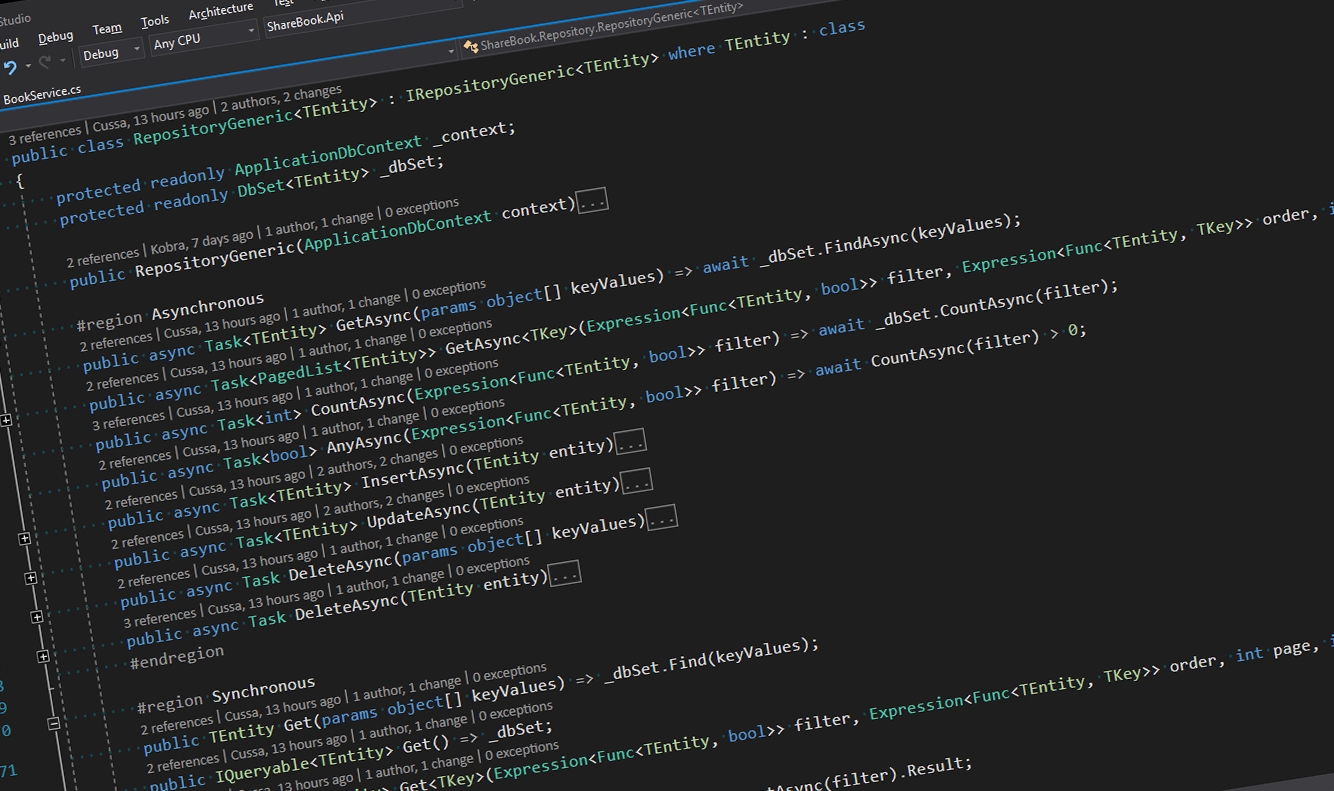
Ao entrar no Slack, fui automaticamente para o canal de back-end e lá tentei ver como estava sendo a interação. (Como eu entrei praticamente no início, posso dizer que eu cheguei lá quando ainda era mato?) Piadas a parte, o início foi a galera vendo um pouco como as coisas poderiam funcionar. O Raffa pediu para a galera ideias de implementação/arquitetura para o back-end. A ideia seria utilizar .Net Core 2.x, C#, Web Api e SQL Server (automaticamente, viramos também a chave de usar o Entity Framework).
Neste momento, entra em cena o Daniel Aloísio. Como ja tinha uma implementação baseada exatamente nesses conceitos, ele enviou essa estrutura como ideia, e assim o projeto se iniciou. Logo após, mais gente começou a se achegar ao projeto e assim as turbinas começaram a funcionar. Aqui, vale um destaque (na minha e na opinião do Raffa): um dos contribuidores está sendo o Walter Cardoso, que chegou já querendo colocar a mão na massa e começou a dar um gás nas atividades.
Uma das coisas interessantes é que como a ideia do projeto é treinarmos nossas habilidades enquanto geramos um projeto de código aberto, eu resolvi fazer isso também. Como estou fazendo cursos relacionados a Gerenciamento de Projetos Ágeis, Como ser um bom gestor, líder e coach, além de assuntos técnicos, resolvi que, além de código, eu poderia utilizar o projeto para treinar essas minhas skills. Apesar de não ser o foco desse artigo, sinto que é importante comentar para explicar algumas decisões que estou tomando ao longo do percurso.
O primeiro Pull Request negado a gente nunca esquece?
Como é um projeto de código aberto, o sistema de funcionamento para as mudanças é através de fork. E assim que veio o primeiro Pull Request (na verdade, seria o terceiro.. mas o primeiro foi Daniel subindo a base do código e o segundo foi eu adicionando o gitignore e retirando as pastas, foi o primeiro PR efetivo com funcionalidade), feito pelo Walter, eu fui fazer um code review. Uma das coisas que tenho tentando treinar bastante é a minha forma de comunicação com as pessoas, principalmente de forma escrita. Afinal, o fato de texto não demonstrar o tom de voz, é praticamente impossível saber qual seria o sentido da frase.
Fiz alguns comentários sobre o código, mas por falta de costume, acabei esquecendo de colocar no GitHub para pedir a revisão dos meus pontos. Com isso, acabou que o foi mergeado no sistema. Após uma conversa entre eu, Raffa e Daniel, decidimos que tentaríamos ter mais code reviews, passando pelo menos pelo meu approve e do Daniel. Dessa forma, além do desenvolvedor, teríamos mais 2 pares de olhos vendo o código.
Logo, acabou que passei os comentários para o Walter via Slack e ele fez um novo PR. Nesse ponto, eu reparei uma coisa: havia alguns pontos que poderiam ser melhorados na arquitetura. Conversei com o Daniel, coloquei algumas ideias no grupo do Slack, fiz algumas perguntas e decidi: vou fazer o refactory para tentar melhorar o código. Isso eram aproximadamente 22h do dia 22 de maio.
O refactory em si
Finalmente chegamos no motivo desse artigo: o refactory. Como ficaria muito complexo explicar tudo no PR que fiz, decidi por tirar as dúvidas iniciais da galera e fazer um artigo mais extenso com a explicação das minhas ideias e conceitos. Uma das coisas que é importante eu registrado, caso você não me conheça, é que eu adoro o conceito de DRY (Don’t Repeat Yourself) e KIS (Keep It Simple, algumas vezes também chamado de KISS… 😉 ), além de ser conhecido como Ceifador: boa parte dos meus commits em projetos que já existem é ceifando linhas de código. Logo, minha implementação tentou fazer isso ao máximo, apesar de que em alguns pontos ainda não está perfeito.
Uma das primeiras coisas que tivemos que fazer foi definir as funções e responsabilidades de cada camada do projeto. Acabamos chegando na estrutura abaixo:
- Domain
- Classes que se referem a tabelas direto
- Regras de Validações
- Api
- Ponto de entrada e faz os redirecionamentos para o Service
- Possuí os ViewModels, quando for necessário (muitos dos parâmetros podem ser utilizados com a classe direto)
- Mappers entre VM e Models
- Service
- Lógica da aplicação
- Validação das entidades (baseada nas regras definidas no Domain)
- Repository
- Acesso a banco através do EF
- Migrations
- Mappings de banco
- Teste
- Se comunica apenas com a Service (e Model) e testa a lógica do código
Essa ideia foi E dada essa ideia, eu senti e comecei a mexer no código. Isso eram aproximadamente 23:15.
Domain
Como não havia uma diretriz de função/responsabilidade nas camadas, acabou que uma das primeiras coisas que reparei foi que várias classes iguais estavam espalhadas pelo projeto. Como não havia motivo disso, eu retirei boa parte das repetições. Trazendo todos os modelos para uma camada separada, as outras poderiam simplesmente referênciar ela e utilizar os dados diretos.
Outra coisa feia foi incluir as regras de validação através de classes especiais chamadas Validators. Elas usam o FluentValidation para gerar as regras que serão posteriormente consumidas pela camada de Service.
Uma outra adição foi uma classe para listas paginadas. Afinal, não faria muito sentido retornar todos os livros do sistema de uma só vez.
E a última alteração foi na classe de Result, que possui as mensagens de validações, assim como o result esperado.
Repository e Service
Com o Domain preparado, fui para o repository. É importante eu comentar que, apesar de ter começado aqui, esse refactory foi executado em conjunto direto com o service, já que alguns métodos que estavam aqui foram para o service, enquanto criava o BaseService, que se liga diretamente com o GenericRepository.
GenericRepository
O conceito de um GenericRepository é abstrair os métodos mais comuns em uma lingaguem “universal”. Levando-se em consideração que o Repository como um todo precisar ser uma camada que apenas abstraí o acesso ao banco, eu comecei a implementar os métodos mais comuns de forma totalmente genérica. Dessa forma, para os métodos básicos de CRUD, os desenvolvedores não precisariam escrever mais nenhum código, dedicando o tempo apenas para gerar as funções de negócio que não suportam o CRUD básico. Nesse ponto, veio uma pergunta:
Async Task<TEntity> ou TEntity: eis a questão.
Eu parei nesse ponto e comecei a pesquisar sobre o quanto vale a pena usar o async Task em diversos casos. Boa parte dos métodos do EF possuem sua versão async, então qual seria a diferença entre utilizar e não utilizar? Depois da leitura interessante deste artigo (https://msdn.microsoft.com/en-us/magazine/dn802603.aspx), onde o autor destrincha o motivo de se usar async, cheguei a seguinte “conclusão”:
De acordo com o que eu li e entendi, a diferença em Async vai ocorrer quando você tem I/O. Logo, a diferença se dá quando há leitura de arquivos, incluindo informações de banco (que no fim, são arquivos). Logo, eu fiz com que todos os métodos que vão acessar o banco (exceto o Get que pega todo mundo ou que usa filtro) usassem a consulta de forma assíncrona no banco. O artigo explica de forma muito interessante como é o funcionamento de thread pools nesse caso, que retorna até que o método seja finalizado, através do uso do await. É interessante notar que em casos de CPU-bound, só haverá diferença real se você utilizar threads para processamento assíncrono. Ou, em alguns casos, para não travar a interface do usuário, técnica muito utilizada com WPF, por exemplo.
Dado isso, nos métodos síncronos, eu simplesmente fiz eles chamarem os métodos Async, com o Result no final. Utilizar a propriedade Result de uma Task é forçar o código a esperar um método async terminar e pegar o retorno dele, mas num método que você não quer que seja assíncrono. Isso signifca que o método Insert vai chamar o InsertAsync e a thread vai ficar alocada no método esperando o Result do InsertAsync.
Um outro detalhe interessante de deixar nota aqui é sobre os métodos de Get. Na minha opinião, um Get é um Get. Você quer pegar algo, e pode utilizar diversos filtros diferentes para fazer isso. Mas no fim, o importante é que você quer pegar algo. Logo, criei os métodos de Get através de overload. Temos um para pegar pelo Id da tabela, um para pegar uma lista paginada, e um que não tem a sua versão async: o Get(). Muitas das implementações que eu vi fazem algo parecido com o seguinte:
public async Task<IEnumerable<TEntity>> GetAll()
{
return await _dbSet.ToListAsync();
}
Lamento informar, mas se você está fazendo isso, você tem um problema sério na sua aplicação. O que muitos desenvolvedores não se atentam é que o _dbSet é um tipo de IQueryable. Ao executar o método ToListAsync, você está tendo um improvement de performance, e isso é bom. Afinal, você está trazendo para a memória da aplicação todos os registros do seu banco. Sim, você leu certo: todos os registros. O conceito do IQueryable define uma árvore de LINQ. No momento que você coloca o ToList() ou ToListAsync(), a query é executada no banco e retorna os dados para o tipo List. Ao colocar a cláusula de Where depois de um ToListAsync (e o mesmo vale para o ToList), você está trazendo todos os dados para a memória da sua aplicação e executando o filtro ali. E foi por isso que não temos o Get() em async. Porque o que queremos é retornar um IQueryable onde você pode montar a sua query LINQ e, apenas depois que ela está toda montada, é que é executada (com os devidos filtros) no banco, retornando apenas os dados que você quer.
Book e User Repository
Seguindo a proposta que apresentei, o repository teria apenas métodos que apresentam uma real necessidade de interação com o banco. Aqui entrariam os métodos que efetuam uma query mais complicada no banco ou chamariam uma procedure. Todos os outros métodos padrões já estão implementados e acessíveis através do GenericRepository. Com isso, nosso código do BookRepository e do UserRepository ficaram assim:
using ShareBook.Domain;
namespace ShareBook.Repository
{
public class UserRepository : RepositoryGeneric<User>, IUserRepository
{
public UserRepository(ApplicationDbContext context) : base(context)
{
}
}
}
using ShareBook.Domain;
namespace ShareBook.Repository
{
public class BookRepository : RepositoryGeneric, IBookRepository
{
public BookRepository(ApplicationDbContext context) : base(context)
{
}
}
}
GenericRepository pronto, foi hora de brincar com o BaseService. Aqui, o construtor recebe o Repository, o UnitOfWork (que irá controlar transações quando necessário) e o Validator. Os métodos de Get(id) e Get(lista paginada) são expostos automaticamente, baseado no Repository, assim como os métodos de Insert, Update e Delete. No caso de Insert e Update, as validações são executadas automaticamente. Há também um método Validate, para caso você precise fazer alguma coisa diferente (como aconteceu no caso do User, que precisava validar se o e-mail já estava cadastrado no sistema).
Com esse approach, o BookService não tem nenhum código, já que até o momento atual ele não possuí nenhuma implementação que não seja CRUD. No caso do UserService, criamos o método GetEmailAndPassword (utilizado para fazer o login, e em processo de mudança para autenticações mais seguras) e um override do Insert para a validação citada acima.
Api
Aqui não foi necessária muita mudança. Apenas ajustes para utilizar as classes do Domain, ajuste no nome dos métodos que seriam chamado do Service, aproveitei e coloquei os métodos de lista paginada para o Book e finalmente coloquei os Validators na lista de referências da bibliteca de Dependency Injection.
Depois de alguns testes utilizando o Swagger da Api (já que os testes ainda não estão fazendo o teste do serviço), e verificar que tudo estava correto, fiz o push para o meu repositório e finalmente o PR para o projeto. Eram 02:06 da manhã e eu fui dormir com a sensação de dever cumprido.
Final da história…?
Não. Refactory é uma metodologia de escrita de código. Sempre podemos melhorar, não existe código perfeito. O código foi aprovado pela galera e já se encontra disponível. Mas o trabalho não acabou. Ainda tem outras ideias que podem ser agregadas ao projeto e algumas delas podem necessitar um novo Refactory.
Ficou interessado em ajudar no ShareBook?
Minha recomendação é: entre no Slack e veja com a galera de lá sobre o que precisa ser feito. Acesse o repositório no GitHub e contribua você também!
Slack: https://sharebookworkspace.slack.com/
Github: https://github.com/SharebookBR
Woowww. Que artigo foda! Tecnicamente impecável. Fácil e agradável de ler. Agradável porque tem sentimento. Eu percebi claramente que vc ama o que faz. E seu texto traz isso. Traz uma energia boa que contagia geral. Parabéns amigão. E obrigado por sua liderança no projeto. Tamo junto 👊,
Pingback: Log de entidades usando o Entity Framework – Hod Studio
Realmente ler este refactory me deixou muito animado, pelo seu empenho em fazer as coisas certas, coesas e simples. Até o momento esta implementação do ShareBook é a que faz mais sentido pra mim ao iniciar um novo projeto. Eu também irei da minhas contribuições la no GitHub.
Parabéns Cussa.